一次基于YOLOv5的深度学习项目,在GPU服务器完成模型训练,在Windows 10下进行图像识别推理(C++)。
零 —— 前言
此篇博客是我亲手做的一次项目记录(2023.7.3~2023.7.14),在GPU服务器完成基于YOLOv5的模型训练,在Windows 10下将训练得到的权重文件作基本处理转化为.onnx文件和.engine文件分别进行C++下的推理,最后并做了简单界面,效果如下图。

本人学术不精,此篇博客可能会因为一些深度学习上的知识不熟悉而造成的表达错误,此博客只是记录此次项目过程,并尽力使其有参考性、使其可复刻。
项目代码放在码云Gitee仓库
壹 —— 环境准备
本项目需要的环境:
- Python环境:YOLOv5所需
- CUDA环境:调用显卡进行显存加速
- OpenCV环境:进行图像处理
我的环境是CUDA12.0,OpenCV4.5.2,训练所用Python3.8.10,本机Windows 10所用Python3.11.4。
下载安装CUDA可参考这篇博客
配置OpenCV和CUDA环境可参考这篇博客。
贰 —— 数据准备
2.1 数据集结构
本项目需要的数据集(不公开):
- 校园内电瓶车463张:435张用于训练,28张用于验证

这个数量上和比例上并不良好,也没有设测试集,建议照片尽量多,并按8:1:1的比例分配在训练集、验证集和测试集。
- 训练集:用于YOLOv5模型调试神经网络;相当于学生的课本,学生根据课本里的内容来掌握知识。
- 验证集:验证集用来查看训练效果;相当于作业,通过作业可以知道不同学生学习情况、进步的速度快慢。
- 测试集:用来测试网络的实际学习能力;相当于考试,考的题是平常都没有见过,考察学生举一反三的能力。
数据集的文件结构应如下:
1 | dataset |
2.2 处理数据集
使用LabelImg进行对图片标记。或自行搜索使用安装教程。
打标签时,选择YOLO格式,生成的是.txt文件,用于模型训练。

打完标签后,在labels文件夹下的train文件夹、val文件夹和test文件夹会生成一个对应images各文件夹的.txt文件,还会生成一个classes.txt文件。故labels文件夹下的各个文件夹会多一个文件。
最后命名此数据集为eleb。
叁 —— 模型训练及分析
3.1 部署YOLOv5
训练模型需要在专业的GPU加速服务器上运行, 请勿尝试在自己的电脑上跑模型。
挑选GPU服务器可参考这篇博客。
3.1.1 使用社区镜像自动部署YOLOv5
我使用的是AutoDL算力云,其社区镜像默认安装了YOLOv5。在算力市场中寻找合适的地区,GPU型号尽量好,按量计费租用。我此次租用的是:芜湖区-RTX3090,1.58r/h,跑四百多张图片估计是四个小时左右。
租用实例后开机,我选择JupyterLab的方式连接服务器。为了方便,我把默认的yolov5文件夹转到(剪贴粘贴)数据盘。有文件如下:

3.1.2 手动部署YOLOv5
建议租用Ubuntu系统,在有Python、Git等环境下,服务器新建文件夹,使用git命令克隆YOLOv5仓库或者网页下载压缩包解压部署。如果有缺少的库可以pip install安装。
1 | git clone https://github.com/ultralytics/yolov5.git |
至此YOLOv5部署完毕。
3.2 上传数据
将我们准备好的数据集压缩成.zip压缩文件,上传到yolov5/data/eleb(数据集根目录,新建文件夹eleb),由于文件比较大,上传速度也比较慢,比较费时间,也可以在服务器上创建文件夹后多选文件上传。
在终端上进入yolov5/data运行下面的指令:
1 | unzip xx.zip |
如果提示有包没下载就去下载。
解压后,复制data文件夹下的coco.yaml,并命名为数据集的名字。在上面我将数据集名字命名为eleb,故复制并命名为eleb.yaml。
将eleb.yaml编辑如下:
1 | # 训练集、验证集、测试集路径设置 |
3.3 配置训练参数
3.3.1 修改train.py文件
回到yolov5/目录,找到train.py文件打开,找到parse_opt()函数,更改部分参数:
1 | # …… |
3.3.2 修改val.py文件
回到yolov5/目录,找到val.py文件打开,找到parse_opt()函数,更改部分参数:
1 | # …… |
3.3.3 修改模型配置
进入yolov5/models/目录,找到train.py设置的模型配置.yaml文件,我这里使用的是yolov5l模型,打开yolov5l.yaml,修改nc(分类数),此项目修改为1:
1 | # …… |
至此训练参数配置完毕。
启动终端,进入yolov5文件夹,我这里是进入autodl-tmp/yolov5/,输入命令启动训练:
1 | python train.py |
如下图即开始训练
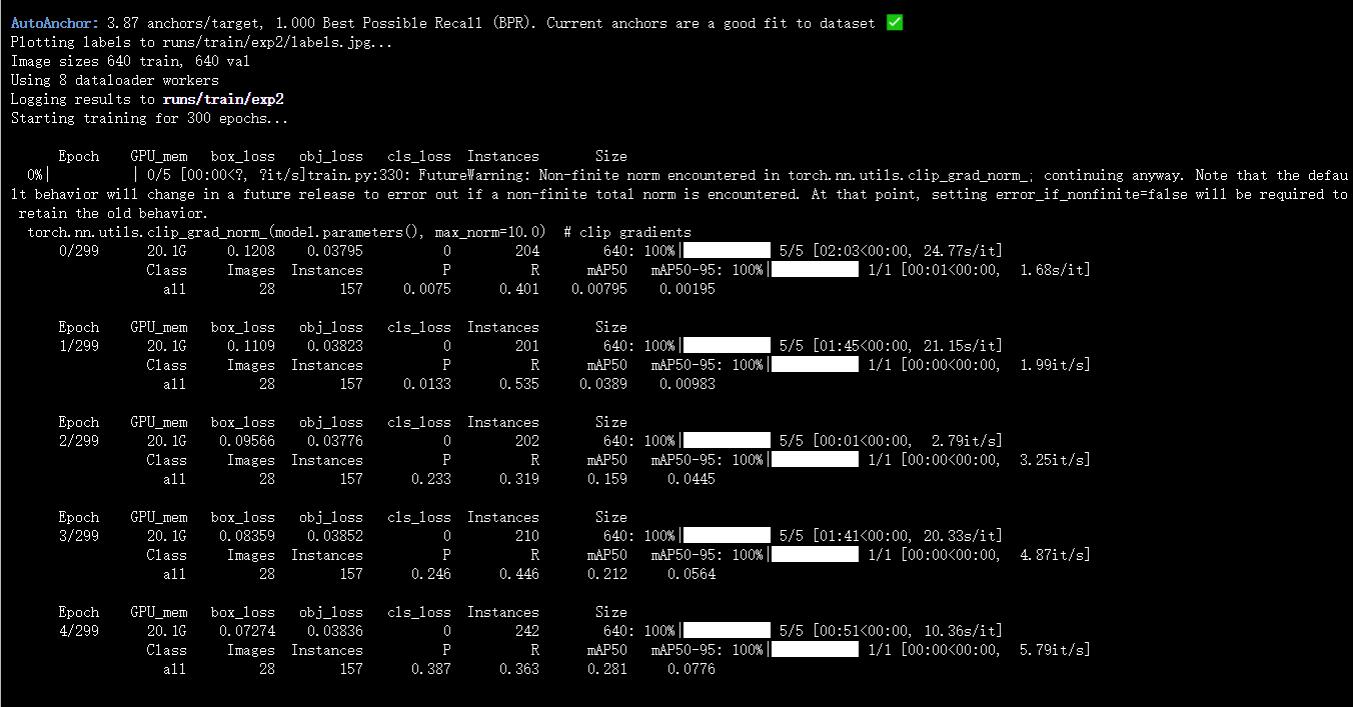

3.4 训练可能出现的问题
如果出现训练过程长时间的R和P值为0或者val/box_loss和val/obj_loss为nan的情况,参考此篇博客。
如果仍不能解决,可以考虑重新手动部署YOLOv5,接着修改参数运行train.py启动训练,如果缺少库就pip install安装。
3.5 训练结果分析
等待训练结束,在 yolov5/runs/train 文件夹就存放在训练的数据,其中weights文件夹中还存放着此次训练的权重文件,用于后续推理。
3.5.1 保存训练结果
在训练结果文件夹(我的是runs/train/exp2)中新建.py文件,输入下面代码,接着使用终端进入runs/train/exp2,使用命令python save.py可以变成压缩包,下载压缩包即下载全部训练结果。
1 | # save.py |
将训练结果下载到电脑上,解压有如下文件:

3.5.2 曲线类分析
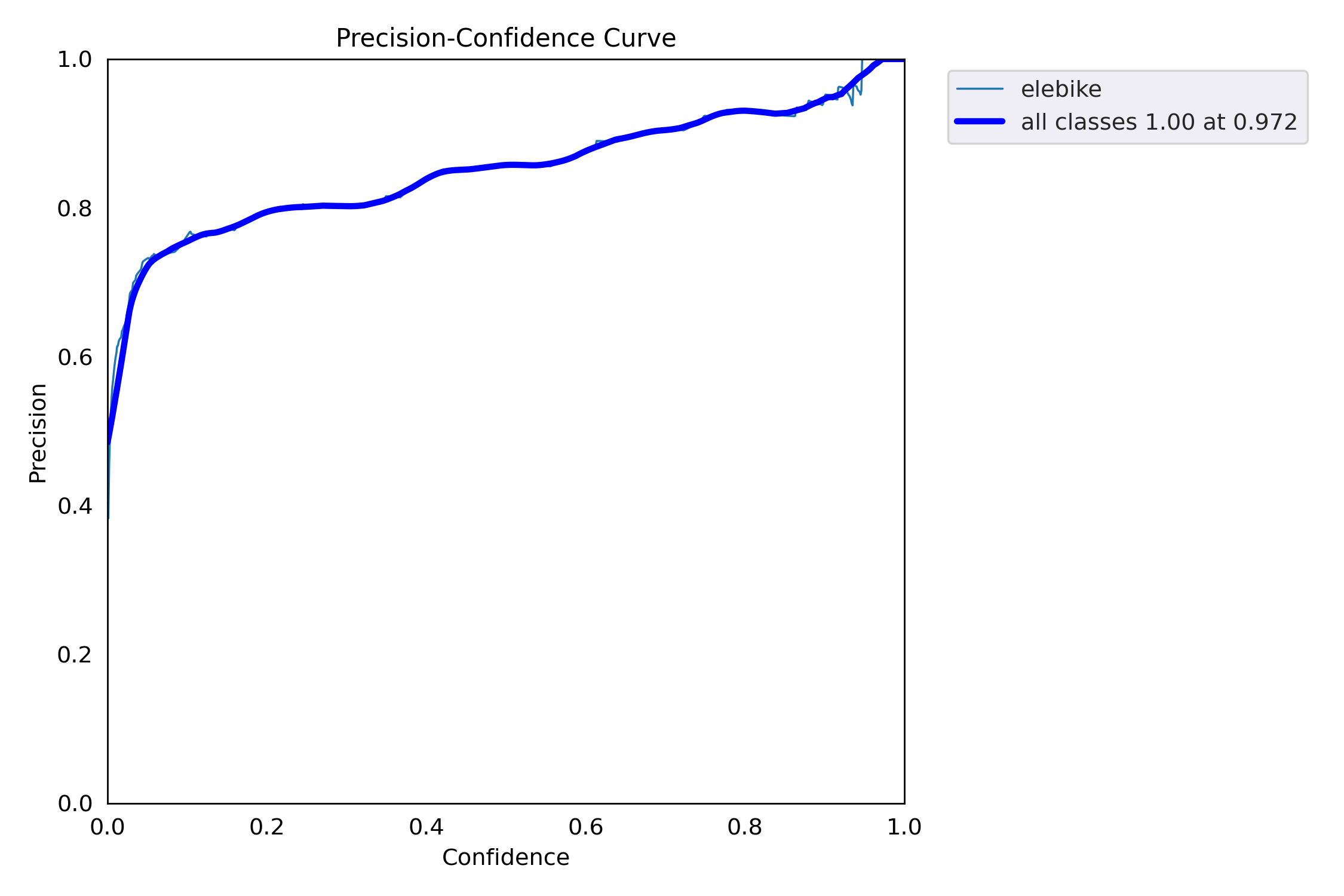
- P_curve:准确率Precision和置信度Confidence的关系图,当设置某置信度时对应某个类别的识别准确率。随着置信度设置越高,某个类别识别准确率越高。
- R_curve:召回率Recall和置信度Confidence的关系图,当设置某置信度时对应某个类别的查找完全的概率。随着置信度设置越高,某个类别能被查找完全的概率越低。

- PR_cruve:准确率Precision和召回率Recall的关系图,尽可能希望准确率高的同时召回率也高,即曲线与坐标轴围成的面积越大,模型越好。

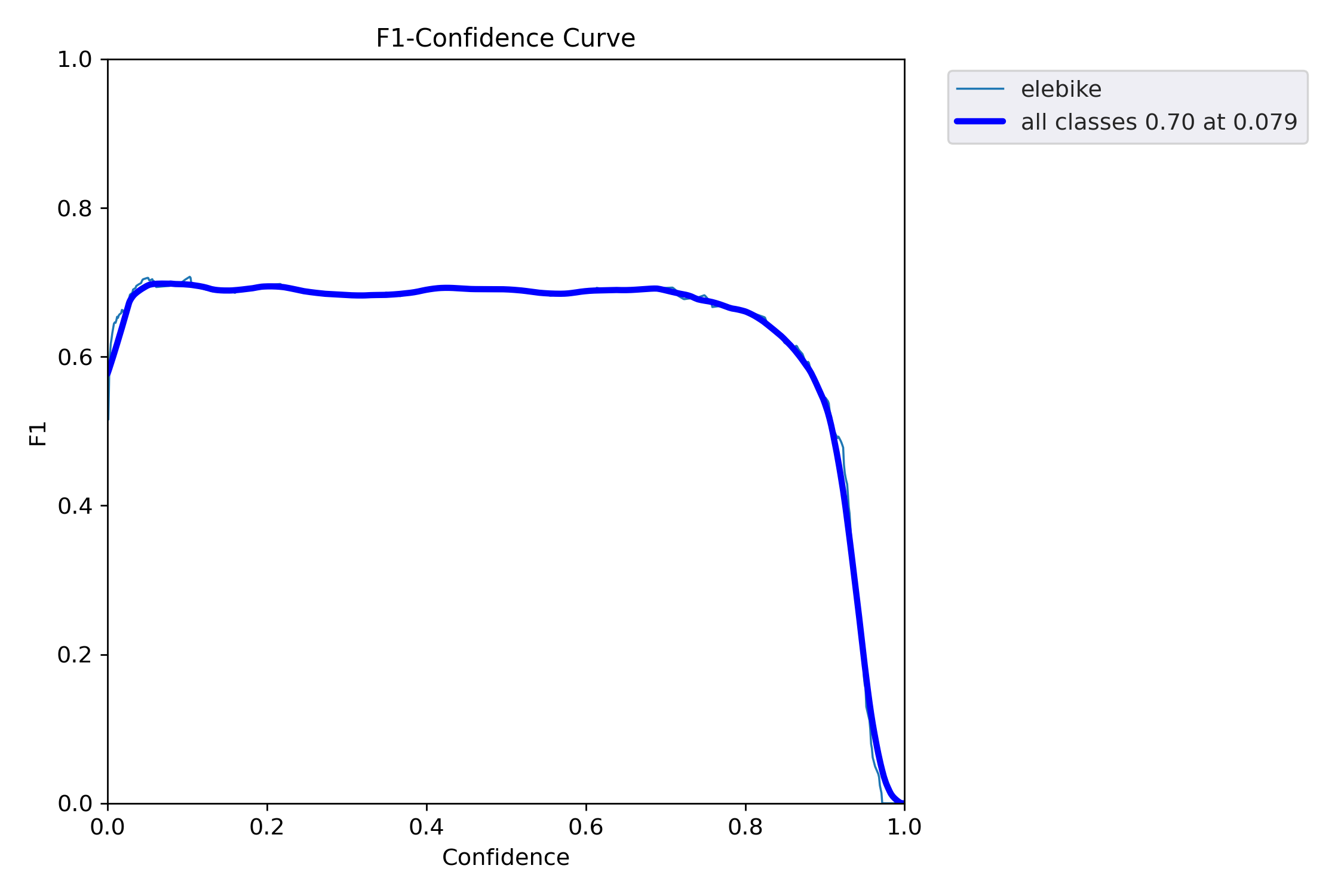
- F1_curve:精确率和召回率的调和平均数,某个分类对应F1的值,1为最好,0为最差。
3.5.3 混淆矩阵分析
- confusion_matrix:矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例,可以方便地看出机器是否将两个不同的类混淆。

3.5.4 标签相关分析

- 左上角为训练集的数据量;
- 右上角是框的尺寸和数量;
- 左下角是打标签目标框中心点位置,由图可知中心点多为中心偏上。
- 右下角是打标签目标框的高和宽,由图可知多聚集在0.2×0.2
3.5.5 训练验证结果分析

前面加train为训练集的情况,加val表示验证集的情况。
-
定位损失box_loss:预测框与标定框之间的误差。
-
置信度损失obj_loss:计算网络的置信度。
-
分类损失cls_loss:计算锚框与对应标定分类是否正确。
-
precision:模型精度。
-
recall:真实为positive的准确率,即正样本有多少被找出来了。
-
mAP:Mean Average Precision,均值平均精度,mAP_0.5表示阈值大于0.5的平均mAP。
-
mAP_0.5:0.95:表示不同IoU阈值(从0.5到0.95,步长0.05)上的平均mAP。
3.5.6 其余分析
-
train_batch、val_batch表示一批次读取的照片数。 -
results.csv存放着每轮训练的数据。
肆 —— 模型转化处理(基于.onnx文件推理)
4.1 转化为.onnx文件
将我们的.pt文件经过服务器上YOLOv5自带的export.py处理后即可得到.onnx文件。即下面的命令格式:
1 | python export.py --weights yolov5s.pt --include onnx |
我输入的是(位于yolov5文件夹):
1 | python export.py --weights runs/train/exp2/weights/best.pt --include onnx |
4.2 通过C++利用.onnx文件进行推理识别
4.2.1 记录处理的数据结构
将置信度阈值confThreshold、NMS非极大值抑制阈值nmsThreshold、目标置信度阈值objThreshold和识别模型路径modelpath打包成结构体,用于识别时参数的配置。
1 | // 自定义配置结构 |
创建YOLOv5类,其成员变量有置信度阈值confThreshold、NMS非极大值抑制阈值nmsThreshold、目标置信度阈值objThreshold,以及输入图片宽度inpWidth、输入图片高度inpHeight两个照片参数,识别种类数num_classes,类名classes;
主要函数为检测函数detect,辅助函数为预测画框函数drawPred和调整图片大小函数resize_image。
1 | // 模型 |
4.2.2 检测识别函数
- 进行预处理:对输入图像(帧)进行大小调整和归一化处理,以便为模型做准备。调整后的图像会被转换为Blob,一个具有NCHW 维度(图像数、通道数、高度、宽度)的 4D 矩阵。
1 | Mat dstimg = this->resize_image(frame, &newh, &neww, &padh, &padw); |
- 模型推理:在Blob上运行模型以获得输出,即边界框和类别概率列表。
1 | vector<Mat> outs; |
- 进行后处理:如果输出超过2维,则会对其进行重塑。对于每个边界框,它会检查对象的置信度是否高于阈值。计算最大类得分,同时检查其是否高于置信度阈值。如果超过了,就会保存边界框、置信度和类ID。
1 | for (int i = 0; i < num_proposal; ++i) |
- 非最大值抑制 (NMS):NMS用于移除重叠的边界框。剩余的边界框在原始图像上绘制。
1 | vector<int> indices; |
4.2.3 预测画框函数
预测画框函数用于将预测函数所得到的目标区域,经OpenCV的工具在图片上绘制出方框。首先传入的参数有置信度,图片的四个角落点,Mat类型图片和类id,接着借助OpenCV的rectangle函数和putText函数绘制。
1 | // 绘制预测目标的边界框 |
4.2.4 主函数
本程序通过main函数的参数进行传参。如C/C++语言语法, argc 是argument count的缩写,表示传入main函数中的参数个数,包括这个程序本身; argv 是 argument vector的缩写,表示传入 main 函数中的参数列表,其中 argv[0] 表示这个程序的名字。
1 | //yolov5-onnx.cpp |
所以当调用该程序时,只需在命令提示符的当前目录下,输入指令格式:
1 | yolov5-onnx.exe best.onnx input.jpg |
伍 —— 模型转化加速处理(基于.engine文件推理)
5.1 转化为.engine文件
5.1.1 通过YOLOv5自带的export.py转换
将我们的.pt文件经过服务器上YOLOv5自带的export.py处理后即可得到.engine文件(可能会自动下载TensorRT)。即下面的命令格式:
1 | python export.py --weights yolov5s.pt --include engine |
我输入的是(位于yolov5文件夹):
1 | python export.py --weights runs/train/exp2/weights/best.pt --include engine |
5.1.2 通过自己下载安装的TensorRT转换
在安装TensorRT后,在TensorRT文件夹下有一个名为 bin 的文件夹,里面存在一个trtexec.exe文件。可以通过这个文件进行文件转换。在 bin 目录启动命令提示符,命令格式如下:
1 | trtexec --onnx=best.onnx --saveEngine=best.engine |
5.2 通过C++利用.engine文件进行推理识别
5.2.1 记录识别结果的数据结构
一个记录识别结果的结构体,包括检测物体置信度 score,目标预测框 box 和类ID class_id 。
1 | struct Result |
5.2.2 日志模块
在构建TensorRT Runtime时需要作为参数传入。日志模块必须继承自nvinfer1::ILogger类。
1 | // TensorRT需要日志 |
5.2.3 计算内存大小模块
一个计算内存大小的辅助函数。
1 | size_t get_memory_size(const nvinfer1::Dims &dims, const int32_t elem_size) |
5.2.4 检测识别模块
基于.engine文件的推理识别涉及到显卡的调用,故需用到CUDA的Context。
CUDA的Context是由CUDA驱动程序创建的数据结构,包含执行CUDA操作所需的所有信息,如设备代码、数据以及线程、内存和硬件设置等资源。每个线程都有一个当前Context,该线程上的所有CUDA操作都在该Context中执行。
- 初始化YOLOv5模型
- 首先从
engine_file_path指定的文件中加载TensorRT引擎。
1 | // 读取TensorRT引擎 |
- 其次,推演运行时
nvinfer1::IRuntime是一切资源的源头,是第一个需要被初始化的对象,注意运行时的初始化需要将辅助模块中定义好的logger作为传入参数。同时这段代码使用unique_ptr来跟踪初始化后的运行时对象。引擎nvinfer1::ICudaEngine存储了模型的权重参数,它的初始化分2步:首先将模型文件读入内存,然后使用运行时的deserializeCudaEngine方法初始化引擎对象。
1 | // 初始化IRuntime和ICudaEngine |
- 最后创建CUDA的context,并为输入和输出绑定分配CUDA内存。引擎的本质是专为TensorRT优化后的模型。可使用
createExecutionContext方法来构建推演环境nvinfer1::IExecutionContext。
1 | std::unique_ptr<nvinfer1::IExecutionContext> context{ mEngine->createExecutionContext() }; |
- 准备模型输入
- 了解模型结构,通过netron.app输入.onnx文件查看自己的神经网络结构。我这里输入名字为
images,尺寸为3×640×640;输出名字为output0,尺寸为1×25200×6。

- TensorRT的模型推演在GPU上进行,需要在显存上为用于计算的数据申请空间。输入尺寸为3×640×640,使用内存大小计算函数得到显存中应当开辟的空间大小,然后使用
cudaMalloc申请显存。其中cuda_mem_input为指向该显存区域的指针。为了方便后续推演,这里使用一个指针数组bindings记录下与推演有关的内存区域。
1 | // 记录与推演相关的内存区域 |
- 同时还需为输出区域计算并开辟内存。模型的输出包含一个或多个对象,必须为每个输出对象分配独立的显存区域。在循环体中,首先通过
getBindingDimensions获得输出每个对象的维度,然后计算其占据的显存区域大小,并调用cudaMalloc函数分配显存,最后将指向该存储区域的指针存入之前创建好的bindings。
1 | std::vector<std::string> output_node_names{ "output0" }; |
- 显存空间初始化完成后,还需要初始化最后一个对象
cudaStream。它用来在异步操作中同步结果。
1 | cudaStream_t stream{ nullptr }; |
- 从
image_file_path中读取图像,将其调整为所需尺寸,并复制到GPU内存中。输入图像在进入神经网络之前,首先会进行预处理操作。典型的预处理操作包括:缩放到指定尺寸、减去均值、归一化、除方差。另外如果模型对输入通道的顺序有要求,预处理也会调整通道顺序。YOLOv5的输入大小为640x640像素,通道顺序为RGB, 预处理也非常简单,像素值除以255即可。
1 | cv::Mat img_bgr = cv::imread(image_file_path); |
- 数据预处理的操作是在HOST(CPU)侧完成,在推演之前还需要将预处理后的数据拷贝到GPU一侧。
1 | if (cudaMemcpyAsync(cuda_mem_input, input_buffer, input_mem_size, cudaMemcpyHostToDevice, stream) != cudaSuccess) |
- 运行推理
- 使用执行Context的
enqueueV2方法异步运行模型。enqueueV2是真正触发模型推演的操作。参数中的bindings是之前记录的指向输入与输出显存的指针数组。stream是在初始化资源章节创建的cudaStream对象,用于同步数据。
1 | bool status = context->enqueueV2(bindings, stream, nullptr); |
- 模型输出后处理
- 首先按照输出数据的规格申请输出内存空间。为输出结果
output0申请了一份内存空间,并将指向这些内存区域的指针存储在output_buffers指针数组中。
1 | std::vector<float *> output_buffers; |
- 接着将输出从GPU内存复制到CPU内存。使用
cudaMemcpyAsync函数。其中参数output_buffers为刚才申请好的内存空间,bindings为GPU一侧的显存空间,output_mem_sizes为输出结果所占据的内存大小,cudaMemcpyDeviceToHost指定了拷贝操作的方向,由于这是一个异步操作,所以要使用stream作为同步数据的依据。
1 | for (size_t i = 0; i < output_mem_sizes.size(); i++) |
- 等待同步,已经调用了3个异步操作函数,因此这里需要使用同步操作来等待执行真正完成。同步之后,模型推演的结果才真正存储在了内存
output_buffers中。
1 | cudaStreamSynchronize(stream); |
- 对输出进行后处理。首先定义三个向量分别存储检测获得的物体边界框
boxes、分值scores与类别IDclass_ids。此次训练的YOLOv5模型有1个输出,即output0。 其本身是一个巨大的矩阵,其行数为25200,代表模型给出的物体检测结果。为此,可以定义一个指针p指向output0,然后通过一个循环来轮询结果。 此次训练中,output0每行具有6个元素:第0~3个元素为物体边界框中心x,物体边界框中心y,物体边界框宽度和物体边界框高度;第4个元素为预测框分值;第5个元素是物体类别ID的概率,可以按照最大值获取到分类结果。
1 | std::vector<float> scores; |
- 使用了OpenCV提供的NMS方法
cv::dnn::NMSBoxes。其中boxes为存储了Rect类的向量,scores为存储了分值的向量,score_threshold为检测分值阈值,nms_threshold为NMS操作的阈值,indices为一个空向量,用来存储NMS的结果。最后按照indices给出的物体序号提取最终结果。
1 | // 执行非最大值抑制以消除具有较低置信度的冗余重叠框 |
- 保存结果:它将包含绘制结果的图像保存下来。
1 | for (auto &r : results) |
5.2.5 主函数设计
此程序主函数与基于.onnx文件推理程序类似,通过main函数的参数进行传参。
1 | //yolov5-engine.cpp |
所以当调用该程序时,只需在命令提示符的当前目录下,输入指令格式:
1 | yolov5-engine.exe best.engine input.jpg |
陆 —— 打包软件
6.1 基于.onnx文件图像推理程序打包
打包程序考虑其可用性,在输出文件的时候做了处理:在当前目录输出一张照片,在output/文件夹也输出一张照片并做名字冲突处理。
1 | //导出名冲突 |
1 | // 备份存储 |
由于主函数设计为可用命令提示符运行,故只需使用Visual Studio的Release版本生成.exe文件,再参考此博客进行打包即可。
打包之后即可移植到其他PC设备使用。
6.2 基于.engine文件图像推理程序打包
同理,打包程序考虑其可用性,在输出文件的时候做了处理:在当前目录输出一张照片,在output/文件夹也输出一张照片并做名字冲突处理。
由于主函数设计为可用命令提示符运行,故只需使用Visual Studio的Release版本生成.exe文件,再参考此博客进行打包即可。
注意一点,由于.engine文件需要调用显卡驱动,故不能移植到别的电脑使用(暂时我是没成功)。
6.3 整体打包
此次项目整体打包采用Qt作为前端页面,将上面两个打包好的程序结合,使用时只需调用指定程序模块即可。具体Qt打包可参考此博客
具体代码不细展开,分享于码云仓库。
柒 —— 总结及后话
实际上,如5.1的步骤,将参数改为.trt,即可导出.trt文件。
1 | trtexec --onnx=best.onnx --saveEngine=best.trt |
至于如何根据.trt文件设计算法进一步进行推测识别,此次项目未能完成,有待补充,深度学习很多方面的知识也有待补充。故此次项目仅能作为一个带有启发性的入门级别的项目。
深度学习是机器学习领域中的一个新的研究方向,旨在让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习试图为数据的高层次摘要进行建模,通过使用多个处理层和对这些层的结果进行线性和非线性的转换,来实现对数据的识别和理解。深度学习在搜索技术、数据挖掘、机器翻译、自然语言处理、多媒体学习、语音、推荐和个性化技术等领域都取得了了很多成果。经过这次项目,我感受到了深度学习的有趣,写下这篇博客,用于记录与分享。