个人整理面向入门基础级别的Python语言学习教程。
一. Python的基本观念
1.1 什么是Python语言
Python是一种 直译的 、 面向对象的 、 拥有许多函数库 的语言。
直译表明它不需要经过像C语言一样的编译过程,直接由直译器运行。这有好处也有坏处,好处是方便简洁直接运行;坏处是没有编译器的错误检查,即运行到某行才知道错误。
面向对象表明它是一门高级语言,具有抽象化的概念(也就是对象),能完成众多工作。Python中一切都是对象,而对象的函数称作方法。
拥有许多函数库表明它有很多内置的套件或者是模块,开源且每个人可贡献,我们直接import调用这些模块即可完成一些复杂的任务。 由于Python的模块众多,此教程只介绍最基本的语法,模块的使用建议查看模块的帮助文档,建议善于查阅资料
当然Python也具有垃圾回收的功能,即程序执行时直译器会主动回收不再需要的动态内存空间,减少程序员犯错的机会。
Python也经历了很多版本的迭代,从最初的Python 2.0到Python 3.0、Python 3.x。Python 3在开发时与Python 2不兼容,所以可以认为是两个独立的版本,但后面官方把Python 3.x版本的特性移植到Python 2.6/2.7x中。本教程的演示代码经过Python 3.11.4测试。
1.2 怎么写Python程序
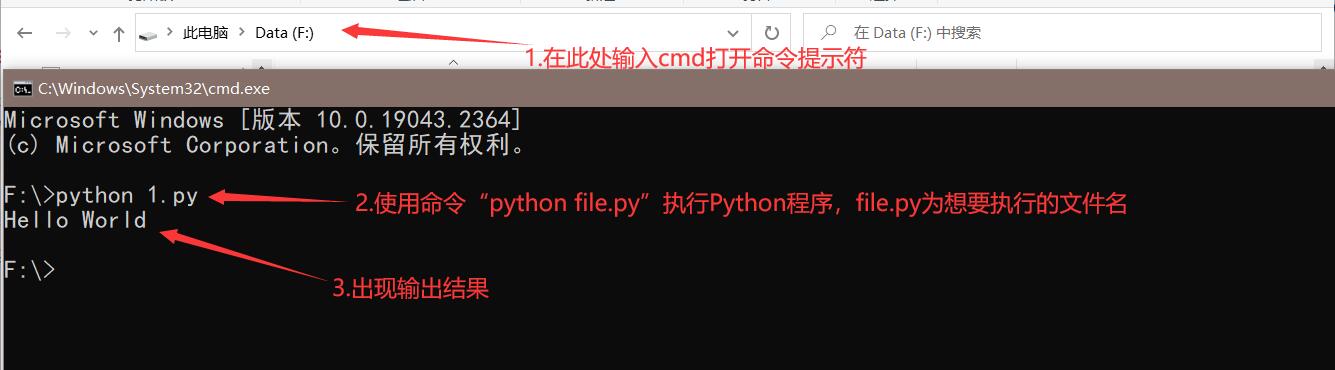
首先具备Python的直译器,即下载安装Python。官网选择尽量较新的Python版本下载。打开下载的Python安装包,选择Customize installation客制化安装,记得勾选下面的“Add python.exe to PATH”。接着默认勾选pip:包管理器,下载包时使用。建议勾选上,再接着更改安装路径,建议安装在非系统盘。最后等待安装完成即可。具体可参考这篇博客
接着编写Python并执行,Python的后缀名为 .py 。在此介绍两种方式编写Python:记事本和Visual Studio Code。
- 记事本方式:新建记事本,命名为
xxx.py,在里面编写Python代码,之后启用命令提示符cmd使用python命令直译运行。
- Visual Studio Code方式:直接编写代码运行。
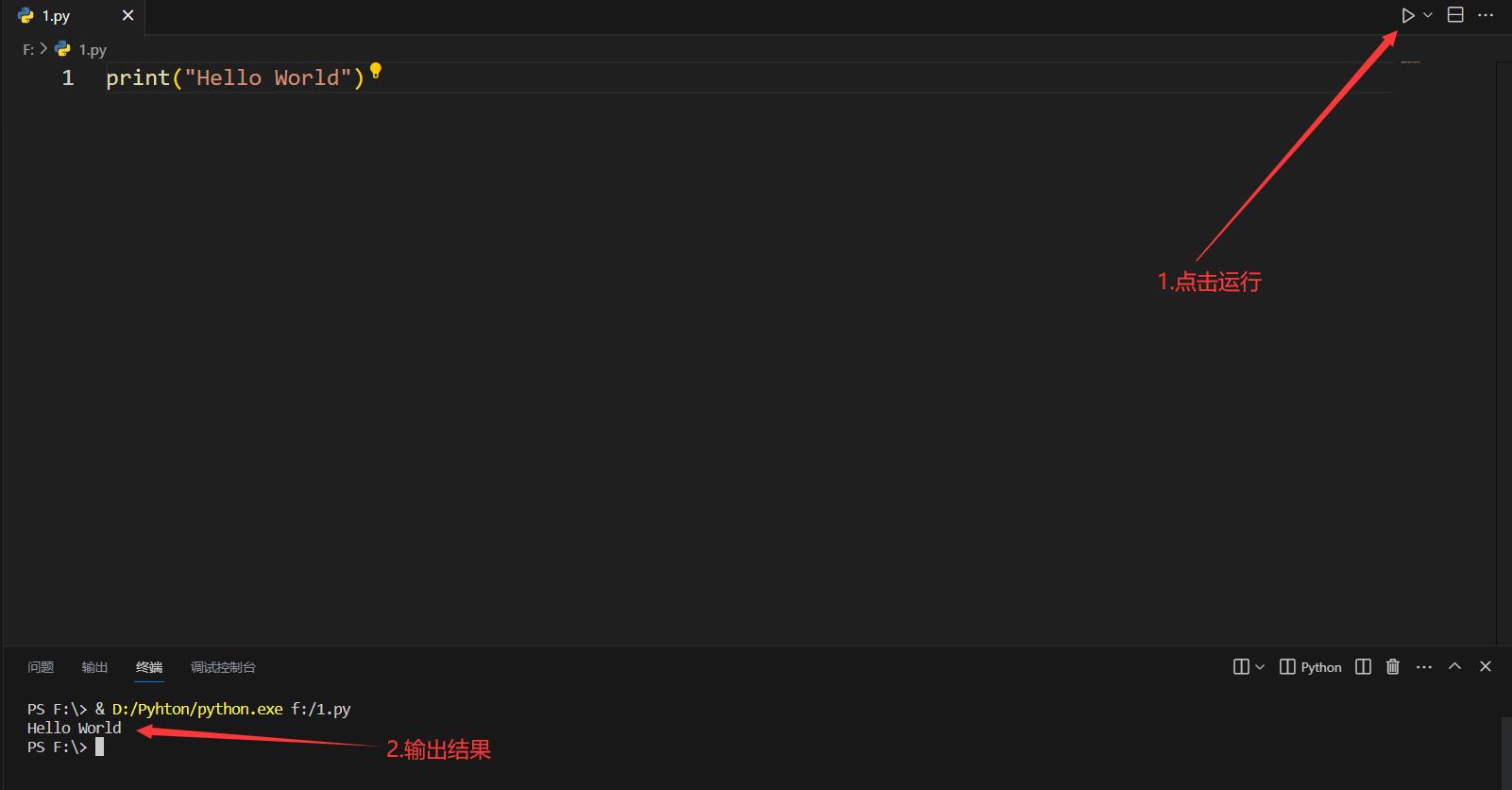
在Python中,使用 # 作为整行注释符号,三个单引号或双引号作为整段注释符号。
同时,Python不像C语言,Python的每句最后不需要添加分号 ; ,还把相同的缩进作为一整个语句块,这些特性会在后面的代码慢慢体现。
1.3 import模块
想使用 Python 源文件或者特殊模块,只需在另一个源文件里执行 import 语句,语法如下:
1 | import module1[, module2[,... moduleN] |
比如引入系统模块: impory sys
在此基础教程上,一般不需要使用import便可满足使用。但是在开发程序时,需要其他模块的支持,便需要 import 。
from … import :语句从模块中导入一个指定的部分到当前命名空间中,语法如下:
1 | from modname import name1[, name2[, ... nameN]] |
from … import * :把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
1 | from modname import * |
在模块间,需要清楚本模块和引入模块的运行。如果想在模块被引入时,模块中的某一程序块不执行,可以用 __name__ 属性来使该程序块仅在该模块自身运行时执行。
举个例子,有两个Python文件:
1 | # a.py |
1 | # b.py |
运行a.py输出:
1 | a.py的main中运行 |
运行b.py输出:
1 | a.py的非main中运行 |
二. 函数
2.1 函数的基本结构
函数的结构应当如下,包括 函数名字function_name 、 参数arguments 和 函数主体Body 。
1 | def function_name(arguments): |
-
def:函数代码块的开头,后接函数名字、参数列表和函数主体。 -
函数名字:标记一个函数的名字。
-
参数列表:当函数被调用时,可以向参数传递值。参数列表包括函数参数的顺序、数量。参数是可选的,也就是说,函数可能不包含参数。
-
函数主体:函数内容以冒号
:开始,并且具有相同的缩进。函数主体包含一组定义函数执行任务的语句。若有返回值的函数使用return返回,没有return相当于返回None。函数主体中遇到返回表示结束函数。
2.2 函数的定义
Python与C语言不一样,不存在函数提前声明一说。即想要调用某函数,必先在前面定义该函数,并不存在调用前先使用函数声明而调用后再函数定义。
定义一个函数十分简单,就如:
1 | def add(a, b): |
2.3 传递参数和调用函数
直接使用函数名加上传递参数即可调用函数。当函数不需要传递参数时:
1 | def doNothing(): |
在Python中,变量是没有类型的,而对象有不同类型的区分。当函数需要传递参数时,参数列表就简单写个变量名:
1 | def add(a, b): |
Python中一切都是对象。
参数传递时,是按 对象 讨论的,分为可变对象传递和不可变对象传递。
-
不可变对象传递(如整数、字符串、元组传递)时,类似于C语言的值传递,传递的只是一个值,并没有影响对象本身。如果在函数中修改对象的值,则是新生成一个对象。
-
可变对象传递(如列表、字典传递)时,类似于C语言的地址传递,或者说引用传递,修改对象的值,外部的对象也受影响。
调用函数时可使用的正式参数类型有:必需参数、关键字参数、默认参数和不定长参数。
- 必需参数须以正确的顺序传入函数。调用时的数量必须和定义时的一样。
1 | def add(a, b): |
- 关键字参数允许函数调用时参数的顺序与声明时不一致。
1 | def sub(a, b): |
- 默认参数会在没有传递参数时使用。
1 | def sub1(a, b = 1): |
- 不定长参数使得一个函数能处理比当初声明时更多的参数。格式如下,加了
*的参数会以元组的形式导入,加了**的参数会以字典的形式导入;如果单独出现星号*,则星号 后的参数必须用关键字传入。不定长参数不过多介绍。
1 | def functionname1(formal_args, *var ): # 元组形式 |
- Python 3.8新增了强制位置参数,举例但不过多介绍。
1 | def f(a, b, /, c, d, *, e, f): |
2.4 内置函数
内置函数有:
abs() |
dict() |
help() |
min() |
setattr() |
|---|---|---|---|---|
all() |
dir() |
hex() |
next() |
slice() |
any() |
divmod() |
id() |
object() |
sorted() |
ascii() |
enumerate() |
input() |
oct() |
staticmethod() |
bin() |
eval() |
int() |
open() |
str() |
bool() |
exec() |
isinstance() |
ord() |
sum() |
bytearray() |
filter() |
issubclass() |
pow() |
super() |
bytes() |
float() |
iter() |
print() |
tuple() |
callable() |
format() |
len() |
property() |
type() |
chr() |
frozenset() |
list() |
range() |
vars() |
classmethod() |
getattr() |
locals() |
repr() |
zip() |
compile() |
globals() |
map() |
reversed() |
__import__() |
complex() |
hasattr() |
max() |
round() |
reload() |
delattr() |
hash() |
memoryview() |
set() |
2.5 匿名函数
Python 使用 lambda 来创建匿名函数。匿名函数即不再使用 def 语句这样标准的形式定义一个函数。
-
lambda只是一个表达式,函数体比def简单很多。 -
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。 -
lambda函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
其语法如下:
1 | lambda [arg1 …] : expression |
举个例子:
1 | add = lambda a, b : a + b |
三. Python的变量与基本运算
3.1 什么是变量
变量是没有类型的,它仅仅是一个对象的引用。而对象具有数据类型。
变量命名应当合法且易懂
-
必须由英文字母、_(下画线)或中文字开头,建议使用英文字母;
-
变量名称只能由英文字母、数字、_(下画线)或中文字所组成;
-
英文字母大小写是敏感的,例如,Name与name被视为不同变量名称;
-
Python的系统或函数保留字不能用作变量名称。
- 系统保留字有:and、as、assert、break、class、continue、def、del、elif、else、except、False、finally、for、from、global、if、import、in、is、lambda、none、nonlocal、not、or、pass、raise、return、True、try、while、with、yield。
如果变量尚未进行设定值或暂时不想存储任何数据,可将值设为 None ,其类型为 NoneType 。
Python的变量同样具有作用域,即变量的使用范围。作用域一共有四种:
-
Local:局部作用域
-
Enclosing:闭包函数外的函数中
如果在一个函数的内部定义了另一个函数,外部的叫外函数,内部的叫内函数。闭包就是在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
-
Global:全局作用域
-
Built-in:内建作用域
使用变量时,以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内建中找。看一个例子:
1 | x = 5 # x 是全局变量 |
由此,使用 global 关键字可以在局部内声明并使用一个全局变量
3.2 运算符
3.2.1 算术运算符
-
四则运算:
+、-、*、/。 -
取余运算:
%,计算除法运算中的余数。 -
整除运算:
//,计算除法运算中的整数部分。 -
次幂运算:
**,计算次幂。
3.2.2 赋值运算符
- 赋值运算:
=,为变量设定值,并由其引申得下表。
| 运算符 | 实例 | 说明 |
|---|---|---|
+= |
a += b |
a = a + b |
-= |
a -= b |
a = a - b |
*= |
a *= b |
a = a * b |
/= |
a /= b |
a = a / b |
%= |
a %= b |
a = a % b |
//= |
a //= b |
a = a // b |
**= |
a **= b |
a = a ** b |
- 等号具有多重使用方式
1 | x = y = z = 10 # 连等,合法 |
3.2.3 比较运算符
| 关系运算符 | 说明 | 实例 | 说明 |
|---|---|---|---|
| > | 大于 | a > b | 检查a是否大于b |
| < | 小于 | a < b | 检查a是否小于b |
| >= | 大于等于 | a >= b | 检查a是否大于或等于b |
| <= | 小于等于 | a <= b | 检查a是否小于或等于b |
| == | 等于 | a == b | 检查a是否等于b |
| != | 不等于 | a != b | 检查a是否不等于b |
3.2.4 位运算符
位运算符是对数据转化为二进制,再逐位进行运算。如,再对每一位进行逻辑运算。
| 运算符 | 描述 | 实例 |
|---|---|---|
& |
按位与运算符,对两个操作数的每一位执行逻辑与操作 | A & B |
\| |
按位或运算符,对两个操作数的每一位执行逻辑或操作 | A \| B |
^ |
按位异或运算符,对两个操作数的每一位执行逻辑异或操作 | A ^ B |
~ |
按位取反运算符,对两个操作数的每一位执行逻辑取反操作 | ~A |
<< |
将操作数的所有位向左移动指定的位数。左移n位相当于乘以2的n次方 | A << n |
>> |
将操作数的所有位向右移动指定的位数。右移n位相当于除以2的n次方 | A >> n |
3.2.5 逻辑运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 逻辑与运算符,如果两个操作数都非零,则条件为真。 | A and B |
| or | 逻辑或运算符,如果两个操作数中有任意一个非零,则条件为真 | A or B |
| not | 逻辑非运算符,用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 | not A |
3.2.6 成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
3.2.7 身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
3.2.8 删除变量
- 使用
del删除变量,回收所占的内存空间。
1 | x = 10 |
3.3 Python的断行
-
Python的语句可以不使用
;,但也可以;进行语句分割。总体上不推荐使用。 -
Python中若语句过长,可以使用
\或#进行分行。
1 | z = (a +\ |
四. Python的基本数据类型
4.1 type()函数
type()可以返回变量的数据类型。如
1 | x = 10 |
4.2 数值数据类型
4.2.1 什么是数值数据类型
数值数据类型用于存储数值。数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。
Python 支持三种不同的数值类型:
-
整型(int):通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。布尔(bool)是整型的子类型。
-
浮点型(float):浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
-
复数(comple):复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型
4.2.2 数值类型的运算
普通的算术运算可以运行在数值数据类型中:
1 | a = 1 |
当浮点数与整数运算时,同样会进行隐式类型转换为更高级的浮点数。
同样也可以使用强制类型转换: int() 、 float() 。
1 | a = 10 |
4.2.3 数值类型的方法
进制转换类型方法:
-
转二进制:
bin() -
转八进制:
oct() -
转十六进制:
hex()
数学方法:
-
abs(x):返回数字的绝对值,如abs(-10)返回 10 -
ceil(x):返回数字的上入整数,如math.ceil(4.1)返回 5 -
exp(x):返回e的x次幂(ex),如math.exp(1)返回2.718281828459045 -
fabs(x):以浮点数形式返回数字的绝对值,如math.fabs(-10)返回10.0 -
floor(x):返回数字的下舍整数,如math.floor(4.9)返回 4 -
log(x):如math.log(math.e)返回1.0,math.log(100,10)返回2.0 -
log10(x):返回以10为基数的x的对数,如math.log10(100)返回 2.0 -
max(x1, x2,...):返回给定参数的最大值,参数可以为序列。 -
min(x1, x2,...):返回给定参数的最小值,参数可以为序列。 -
modf(x):返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 -
pow(x, y):相当于x**y运算后的值。 -
round(x [,n]):返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。其实准确的说是保留值将保留到离上一位更近的一端。 -
sqrt(x):返回数字x的平方根。
除此之外还有三角函数、随机数函数等……
4.3 布尔值数据类型
- Python的布尔值(Boolean)数据类型具有两种值:True(真)或False(假)。数据类型代号是bool。
1 | x = True |
- 如果使用类型转换,True对应1,False对应0。
4.4 字符串数据类型
4.4.1 什么是字符串数据类型
- Python的字符串没有严格规定是单引号还是双引号,只要匹配即可。其数据类型代号是str。如果字符串中有单引号,为了避免出错,使用双引号。
1 | x = 'python' |
- 如果字符串长度大于一行,可以使用三个单引号或三个双引号包夹。
1 | x = '''xxxxxxxxxxxxxxxxx |
- Python 不支持单字符类型,单字符在Python中也是作为一个字符串使用。
4.4.1 字符串的运算
- 字符串的连接可以直接使用
+运算。
1 | x = '1' |
- 字符串可以直接使用
*运算,表示复制该字符串多少次
1 | x = '1' |
- 字符串可以使用
[]索引获取字符串中的字符,从0数起,-1 为从末尾的开始位置。
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| h | e | l | l | o |
| -5 | -4 | -3 | -2 | -1 |
1 | str = "hello" |
- 字符串可以使用
[:]截取字符串的一部分,遵循左闭右开,-1 为从末尾的开始位置。。
1 | str = "hello" |
- 可以使用
in或not in判断某字符是否在字符串中。
1 | str = "hello" |
4.4.2 字符串的类型转换
- 强制转换为字符串:
str()函数。
1 | x = 111 # x为111,是整型 |
- 字符串强制转换为整数:
int()函数。
1 | x = '111' # x为111,是字符串 |
- 字符串转换为码值:
chr(x)函数返回x的ASCII码值,ord(x)函数返回x的Unicode码值。
4.4.3 转义字符
- 转义字符
| 转义字符 | 十六进制值 | 意义 |
|---|---|---|
\' |
27 | 单引号 |
\" |
22 | 双引号 |
\\ |
5C | 反斜杠 |
\a |
07 | 响铃 |
\b |
08 | BackSpace键 |
\f |
0C | 换页 |
\n |
0A | 换行 |
\o |
八进制表示 | |
\x |
十六进制表示 | |
\r |
0D | 光标移到最左 |
\t |
09 | Tab键 |
\v |
0B | 垂直定位 |
- 在字符串前加
r,可以让转义字符不被转义。
1 | str1 = "Hello\nWorld" # 换行符生效 |
4.4.4 字符串的函数方法
字符串的函数方法有许多,此处列出常用的几个。
-
count(str, beg=0,end=len(string)),返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数。 -
endswith(suffix, beg=0, end=len(string)),检查字符串是否以 suffix 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 suffix 结束,如果是,返回 True,否则返回 False。 -
expandtabs(tabsize=8),把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 -
find(str, beg=0, end=len(string)),检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1。 -
index(str, beg=0, end=len(string)),跟find()方法一样,只不过如果str不在字符串中会报一个异常。 -
isalnum(),如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False。 -
isalpha(),如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False。 -
isdigit(),如果字符串只包含数字则返回 True 否则返回 False。 -
isnumeric(),如果字符串中只包含数字字符,则返回 True,否则返回 False。 -
isspace(),如果字符串中只包含空白,则返回 True,否则返回 False。 -
join(seq),以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串。 -
len(string),返回字符串长度。 -
ljust(width[, fillchar]),返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 -
lower(),转换字符串中所有大写字符为小写。 -
max(str),返回字符串 str 中最大的字母。 -
min(str),返回字符串 str 中最小的字母。 -
replace(old, new [, max]),把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 -
rfind(str, beg=0,end=len(string)),类似于 find()函数,不过是从右边开始查找。 -
rindex( str, beg=0, end=len(string)),类似于 index(),不过是从右边开始。 -
rjust(width,[, fillchar]),返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串。 -
rstrip(),删除字符串末尾的空格或指定字符。 -
split(str="", num=string.count(str)),以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串。 -
startswith(substr, beg=0,end=len(string)),检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 -
upper(),转换字符串中的小写字母为大写
具体的函数解释用法可以边用边搜索。
五. Python的输入和输出
5.1 辅助帮助说明输出
- 使用
help()函数可以列出Python指令或函数的使用说明。
5.2 输出
5.2.1 通过print()函数输出
该函数的语法格式为: print(*args, sep=' ', end='\n', file=None, flush=False)
-
*args:输出的数据,可以输出多个,使用逗号隔开。 -
sep:表示输出多个数据时的分隔字符,默认是空格。 -
end:当数据输出结束时插入的字符,默认是插入换行。 -
file:数据输出位置,默认是sys.stdout,也就是屏幕。 -
flush:是否清除数据流的缓冲区,默认是不清除。
1 | x = 10 |
1 | 输出结果:15.0 10,1.5 |
5.2.2 格式化print()的输出
可以使用这样的格式输出: print("输出格式字符串" % (变量)) ,输出格式字符串中,与C语言类似。
-
%d表示格式化整数输出。 -
%f表示格式化浮点数输出。 -
%x表示格式化16进制数输出。 -
%o表示格式化8进制数输出。 -
%s表示格式化字符串输出。
1 | x = 10 |
1 | 输出结果: |
与C语言类似,在控制浮点数的输出时,有如下语法:
%nd:格式化整数输出。若n不带符号表明保留n格空间,保留空间不足将完整输出数据。若n带正号表明输出在左边加上符号,若n带负号表示数据靠左输出。
1 | x = 11111 |
-
%no:格式化八进制输出。若n不带符号表明保留n格空间,保留空间不足将完整输出数据。若n带正号表明输出在左边加上符号,若n带负号表示数据靠左输出。 -
%nx:格式化十六进制输出。若n不带符号表明保留n格空间,保留空间不足将完整输出数据。若n带正号表明输出在左边加上符号,若n带负号表示数据靠左输出。 -
%ns:格式化八进制输出。若n不带符号表明保留n格空间,保留空间不足将完整输出数据。若n带负号表示数据靠左输出。
1 | x = "Hello" |
%m.nf:格式化浮点数输出。m表示保留多少格数输出(包括小数点),n表示小数部分保留位数。若带上正号表明输出在左边加上符号,若带上符号表明数据靠左输出。
1 | x = 3.14159 |
5.2.3 format()函数
使用 format() 函数的输出格式为: print("输出格式字符串" .format(变量, ...))
-
输出格式字符串中输出变量的位置使用
{}表示。 -
{}中填入!a(使用 ascii()),!s(使用 str()) 和!r(使用 repr()) 可以用于在格式化某个值之前对其进行转化。 -
格式内容如下
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} |
3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} |
+3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} |
-1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} |
3 | 不带小数 |
| 5 | {:0>2d} |
05 | 数字补零(填充左边,宽度为2) |
| 5 | {:x<4d} |
5xxx | 数字补x(填充右边,宽度为4) |
| 10 | {:x<4d} |
10xx | 数字补x(填充右边,宽度为4) |
| 1000000 | {:,} |
1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} |
25.00% | 百分比格式 |
| 1000000000 | {:.2e} |
1.00e+09 | 指数记法 |
| 13 | {:10d} |
13 | 右对齐,宽度为10 |
| 13 | {:<10d} |
13 | 左对齐,宽度为10 |
| 13 | {:^10d} |
13 | 中间对齐,宽度为10 |
| 11 | {:b} |
1011 | 二进制表示 |
| 11 | {:d} |
11 | 十进制表示 |
| 11 | {:o} |
13 | 八进制表示 |
| 11 | {:x} |
b | 十六进制表示 |
| 11 | {:#x} |
0xb | 十六进制表示 |
| 11 | {:#X} |
0xB | 十六进制表示 |
5.2.4 dir()函数
通过 dir() 函数可以列出Python的函数。
其格式为: dir(__builtins__) 。
1 | a = 10 |
再结合 help() 函数即可了解每个函数的意义。
5.3 输入
通过 input() 函数输入一行文本。
该函数的格式为: value = input("promt:")
-
value:输入数据存入到该变量中,不论输入什么,value都是字符串数据类型,需要进行处理。
-
promt:输入提示词。
1 | a = input("请输入一个数字:") |
六. Python的条件结构
6.1 if语句
if语句的基本语法如下:
1 | if (条件判断): |
如果条件判断是True,则执行程序代码区块,如果条件判断是False,则不执行程序代码区块。如果程序代码区块只有一道指令,可将上述语法写成: if(条件判断): 程序代码
实际上,Python的条件结构可以不带 () ,但此教程带上了 () ,为了看起来更清晰。
在Python内是使用缩进方式区隔if语句的程序代码区块,编辑程序时可以用Tab键内缩或是直接内缩4个字符空间,表示这是if语句的程序代码区块。
1 | age = 18 |
实际上不一定非得缩进4格字符空间,任意相同缩进的连续语句都可看作是同一代码块。
6.2 if-else语句
程序设计时更常用的功能是条件判断为True时执行某一个程序代码区块,当条件判断为False时执行另一段程序代码区块,此时可以使用if…else语句,它的语法格式如下:
1 | if (条件判断): |
如果条件判断是True,则执行程序代码区块一,如果条件判断是False,则执行程序代码区块二。
6.3 if-elif-else语句
当程序进行多重判断时,可以使用if-elif-else语句,它的语法格式如下:
1 | if (条件判断一): |
如果条件判断一是True则执行程序代码区块一,然后离开条件判断。否则检查条件判断二,如果是True则执行程序代码区块二,然后离开条件判断。如果条件判断是False则持续进行检查,上述elif的条件判断可以不断扩充,如果所有条件判断是False则执行程序代码区块。
举个例子,分数采取A、B、C、D、F,通常90-100分是A,80-89分是B,70-79分是C,60-69分是D,低于60分是F。
1 | score = int(input("请输入你的分数:")) |
6.4 嵌套的if语句
if语句中有其他的if语句,称作if的嵌套。
1 | if (条件判断一): |
七. Python的循环结构
7.1 for循环
for循环的一般格式如下:
1 | for variable in sequence: |
for循环可以遍历任何可迭代对象,如一个列表、元组或者一个字符串。
这个“sequence”可以配合 range() 函数使用,完成一个计数作用:
1 | for number in range(1, 6): |
注意, range() 函数区间左闭右开,其作用是生成一个数列,它有以下形式:
1 | range(6) # 生成0到5,步长为1的数列 |
同时,for循环可以使用else语句:
1 | for item in iterable: |
当循环执行完毕(即遍历完 iterable 中的所有元素)后,会执行 else 子句中的代码,如果在循环过程中遇到了 break 语句,则会中断循环,此时不会执行 else 子句。可以查看下面这两个例子:
1 | for x in range(6): |
1 | 输出结果: |
7.2 while循环
while 语句的一般形式如下:
1 | while( condition is true ): |
此处 condition 为表达式,只有当循环条件为真,即表达式为真,就执行循环体语句。循环体可以是一条语句,也可以是一个语句块(用花括号包起来)。 while 循环的特点是先判断条件表达式,后执行循环体语句。
while 语句的运行顺序是:从上至下,先判断条件表达式是否为真,为真则执行循环体。循环体运行完后再次判断条件表达式,为真则执行循环体。一直循环直至判断条件表达式为假。
while 括号里的 condition 条件表达式实际上也会被执行的,如果条件表达式是赋值语句(赋值成功则表达式为真)、自增自减等也会生效。
同时,while循环也可以使用else语句:
1 | while condition: |
举个栗子:
1 | count = 0 |
1 | 输出结果: |
7.3 break、continue和pass
break语句可以跳出for和while的循环体。如果从for或while循环中终止,任何对应的循环 else 块将不执行。
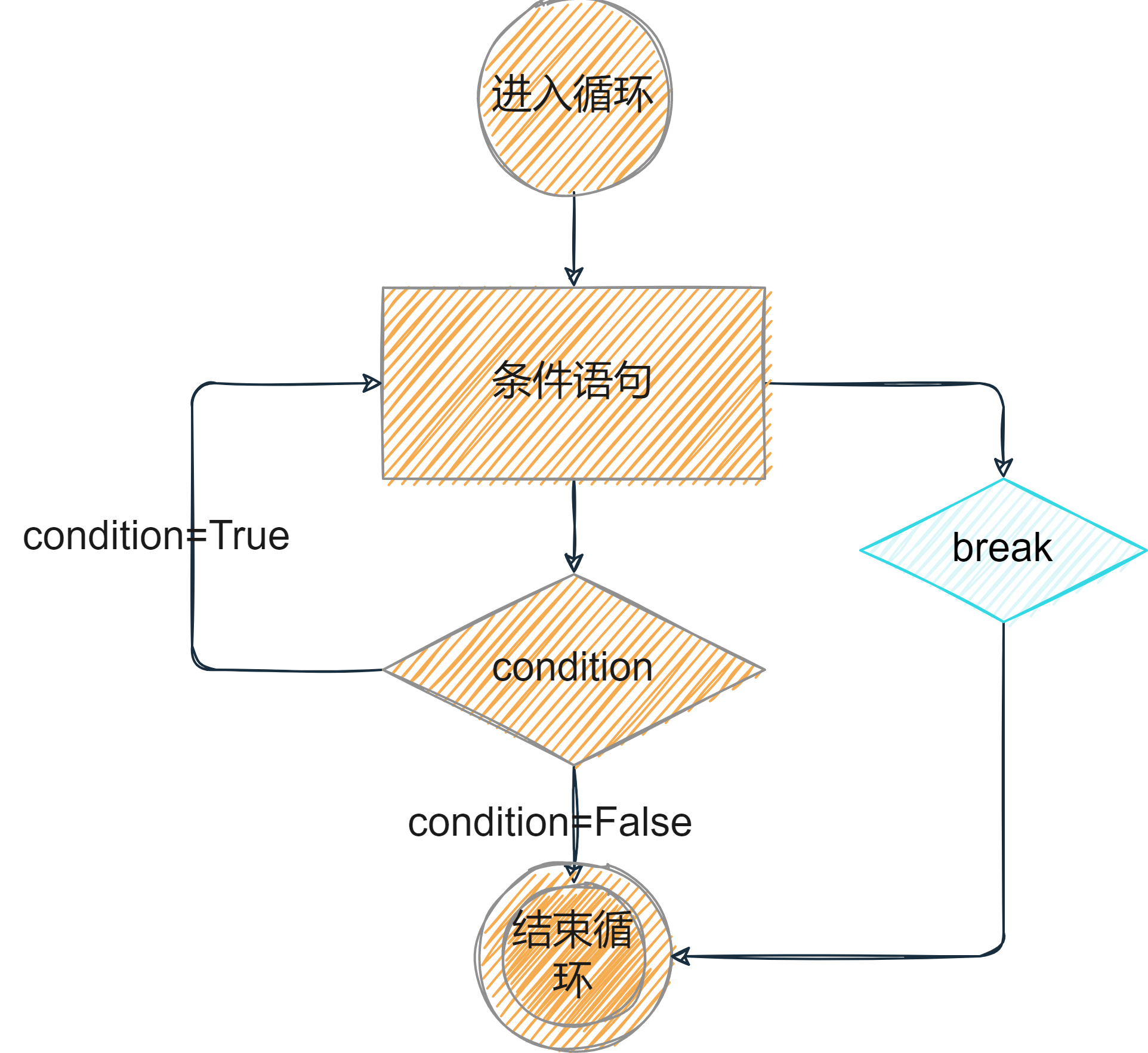
continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环。

pass语句不做任何事情,一般用做占位语句。
1 | for i in range(100): |
八. Python面向对象
8.1 面向对象的相关概念
这里有一些关于面向对象的概念:
-
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
-
方法:类中定义的函数。
-
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
-
数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
-
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
-
局部变量:定义在方法中的变量,只作用于当前实例的类。
-
实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
-
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
-
实例化:创建一个类的实例,类的具体对象。
-
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
8.2 类的定义
语法格式如下:
1 | class ClassName: |
比如,我有一个类,它是描述狗的:
1 | class Dog: |
对于属性而言,公有属性一般是基本属性,在类外部可以直接访问(比如 dog.weight );私有属性不可以在类外部访问(比如 dog.__name 是不允许的),在类内部的属性中使用时 self.__name 。同理方法也有公有和私有之分,私有方法以两个下划线开头。
对于类的方法而言,与普通的函数只有一个特别的区别,就是类的方法必须有一个额外的第一个参数名称, 按照惯例它的名称是 self 。 self 代表了类的实例,代表当前对象的地址。
实际上也不非得是 self ,全部换成别的也行。
8.3 类的方法
8.3.1 构造方法
构造方法的函数名为 __init__ ,语法像这样:
1 | def __init__(self): |
类定义了 __init__() 方法,类的实例化操作会自动调用 __init__() 方法。如上面的狗类,给他完善一下:
1 | class Dog: |
8.3.2 其他方法
有构造方法,自然也有析构方法,他们是对立的。析构方法是释放对象时使用。一般隐式自动调用,函数名为 __del__ 。
类还有一些方法:
-
__repr__: 打印,转换 -
__setitem__: 按照索引赋值 -
__getitem__: 按照索引获取值 -
__len__: 获得长度 -
__cmp__: 比较运算 -
__call__: 函数调用 -
__add__: 加运算 -
__sub__: 减运算 -
__mul__: 乘运算 -
__truediv__: 除运算 -
__mod__: 求余运算 -
__pow__: 乘方
8.4 类的继承
类的继承允许一个子类继承另一个类(称作父类),继承父类的属性和方法。集成的语法如下:
1 | class DerivedClassName(BaseClassName): |
拿回上面的例子,狗类应该是继承自动物类的,因为狗包含在动物里。而动物都有重量这个属性;在狗类里,除了继承重量这一属性,还可以添加新的属性,比如颜色:
1 | class Animal: |
实际上,还可以继承多个父类,语法如下:
1 | class DerivedClassName(Base1, Base2, Base3): |
如狗类从动物类里继承得到重量这一属性,同时也可以从花类里继承得到颜色这一属性,虽然会有点怪,但这确实可以。
1 | class Animal: |
即使狗类里面没有属性,但是通过继承可以得到想要的属性。
但是如果继承太多,方法名字重复了或者父类提供的方法不能满足需求,可以进行方法重写。
1 | class Animal: |
上述代码则对 about() 函数进行了重写,以满足狗类的需求。
重写方法或者重写运算符可以实现一些特殊的功能。
但是对于构造函数,子类不重写 __init__() ,实例化子类时,会自动调用父类定义的 __init__() 。如果重写了 __init__ 时,实例化子类,就不会调用父类已经定义的 __init__ 。还有一种情况,如果重写了 __init__() 函数,仍想调用父类构造方法时,可以这样写:
1 | super(子类, self).__init__(...) |
九. 列表 List
9.1 什么是列表
Python的列表可以存储相同数据类型的数据,也可以存储不同数据类型的数据。
定义列表的语法格式为: listName = [元素1, …, 元素n]
列表的每一个数据称作元素,置于括号 [] 中,用逗号隔开。
其中空列表为没有任何元素的列表。
同样,当我们不需要这个列表时,使用 del 删除列表。
9.2 列表的运算和方法
9.2.1 输出列表
当我们有一个列表时,直接使用print()函数即可输出整个列表。
1 | list = [1, 2, 3] |
9.2.2 读取、修改和删除列表元素
可以通过列表名称与索引读取列表元素的内容,元素的索引值从0开始。修改同理,只需要更改存储的数据即可。
当索引值为负值时,表示从列表结尾数起,-1为最后一个元素,-2为最后第2个元素。
1 | list = [1, 3, 5, 7] |
同时可以使用 in 运算符判断某元素是否在列表中:
1 | list = [1, 3, 5, 7] |
如果希望删除列表的元素,同样使用 del 进行。
-
del list[i]:删除索引为i的元素。 -
del list[start:end]:删除索引从start到end-1的所有元素。 -
del list[start:end:step]:每隔step,删除索引从start到end-1的元素。
1 | list = [1, 3, 5, 7, 9] |
9.2.3 列表切片
在设计程序时,常会需要取得列表前几个元素、后几个元素、某区间元素或是依照一定规则排序的元素,所取得的系列元素也可称子列表,这个过程也称列表切片(list slices)。
-
list[start:end]:读取从索引start到(end-1)索引的列表元素。 -
list[:n]:取得列表前n个。 -
list[n:]:取得列表索引n到最后。 -
list[-n:]:取得列表后n名。 -
list[:]:取得所有元素。 -
list[start:end:step]:每隔step,读取从索引start到(end-l)
索引的列表元素。
9.2.4 列表的统计方法
max():取得列表的最大值。
1 | list = [1, 2, 3] |
min():取得列表的最小值。
1 | list = [1, 2, 3] |
sum():取得列表的总和。
1 | list = [1, 2, 3] |
9.2.5 列表的元素个数
len():判断列表中元素个数。
1 | list = [1, 2, 3] |
也可通过 len() 函数判断列表是否为空。
9.2.6 列表的加法、乘法
列表与列表相加表示列表的结合。
1 | list1 = [1, 2, 3] |
列表与数字相乘表示列表元素重复多少次。
1 | list = [1, 2, 3] |
9.3 列表的其他方法
-
list.append(obj):在列表末尾添加新的对象。 -
list.count(obj):统计某个元素在列表中出现的次数。 -
list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。 -
list.index(obj):从列表中找出某个值第一个匹配项的索引位置。 -
list.insert(index, obj):将对象插入列表。 -
list.pop([index=-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。 -
list.remove(obj):移除列表中某个值的第一个匹配项。 -
list.reverse():反向列表中元素。 -
list.sort(key=None, reverse=False):对原列表进行排序。 -
list.clear():清空列表。 -
list.copy():返回复制后的新列表。有兴趣可了解深拷贝和浅拷贝。
具体的函数解释用法可以边用边搜索。
十. 元组 Tuple
10.1 什么是元组
Python的元组与列表类似,不同之处在于元组的元素 不能修改 。元组使用小括号 ( ) ,列表使用方括号 [ ] 。
定义元组的语法格式为: tupName = (元素1, 元素2, ...)
元组的每一个数据称作元素,置于括号 () 中,用逗号隔开。如果元组中只包含一个元素时,需要在元素后面添加逗号 , ,否则括号会被当作运算符使用。
1 | tup = (1,) |
其中空元组为没有任何元素的元组。
同样,当我们不需要这个元组时,使用 del 删除元组。
10.2 元组的运算和方法
10.2.1 输出元组
当我们有一个元组时,直接使用print()函数即可输出整个元组。
1 | tup = (1, 2) |
10.2.2 读取元组元素
元组同样通过下标索引访问元组中的值。与列表类似。
但通过索引修改元组元素的操作是不被允许的,但是可以通过 + 进行元组的拼接。
1 | tup1 = (1, 2) |
同时也不允许删除元组中的元素值,只能通过 del 删除整个元组。
10.2.3 元组截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素。
-
tup[start:end]:读取从索引start到(end-1)索引的列表元素。 -
tup[:n]:取得列表前n个。 -
tup[n:]:取得列表索引n到最后。 -
tup[-n:]:取得列表后n名。 -
tup[:]:取得所有元素。 -
tup[start:end:step]:每隔step,读取从索引start到(end-l)
索引的列表元素。
10.2.4 列表的统计函数
max():取得元组的最大值。
1 | tup = (1, 2, 3) |
min():取得元组的最小值。
1 | tup = (1, 2, 3) |
10.2.5 元组的元素个数
函数 len() 计算元组中元素个数。
10.2.6 元组的加法、乘法
元组支持 + 、 += 、 * 运算。
1 | tup1 = (1, 2) |
tup3 就是一个新的元组,它包含了 tup1 和 tup2 中的所有元素。
1 | tup1 = (1, 2) |
tup1 就变成了一个新的元组,它包含了 tup1 和 tup2 中的所有元素。
1 | tup1 = (1, 2) |
乘法的作用依然是复制。
十一. 字典 Dict
11.1 什么是字典
字典是另一种可变容器模型,由键值对组成,且可存储任意类型对象。
字典的每个键值对用冒号 : 分割,每个对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
1 | d = {key1 : value1, key2 : value2, ...} |
需要注意的是,键值对的键必须是唯一的,值可以不唯一。 创建时如果同一个键被赋值两次,后一个值会被记住。
键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行。
同时创建空字典时,可以使用 d = {} 直接创建,也可以使用 d= dict() 函数创建。所以字典的名字不能取dict。
11.2 字典的运算和方法
11.2.1 输出字典
直接使用 print() 输出:
1 | d = {'apple' : '苹果', 'banana' : '香蕉'} |
11.2.2 读取、修改和删除字典
与列表、元组使用索引值不同,字典需要把键放到方括号中。如果访问了字典里没有的键,就会报错。
1 | d = {'apple' : '苹果', 'banana' : '香蕉'} |
修改字典内容也是直接使用键访问设定新值:
1 | d = {'apple' : '苹果', 'banana' : '香蕉'} |
向字典添加新内容的方法是增加新的键值对:
1 | d = {'apple' : '苹果', 'banana' : '香蕉'} |
删除已有键值对如下:
1 | d = {'apple' : '苹果', 'banana' : '香蕉'} |
字典还有删除整个字典和清空字典的功能:
1 | d = {'apple' : '苹果', 'banana' : '香蕉'} |
11.2.3 字典的键值对数
函数 len() 计算字典中键值对数。
11.3 字典的方法
-
dict.clear():删除字典内所有元素 -
dict.copy():返回一个字典的复制 -
dict.fromkeys():创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 -
dict.get(key, default=None):返回指定键的值,如果键不在字典中返回 default 设置的默认值 -
key in dict:如果键在字典dict里返回true,否则返回false -
dict.items():以列表返回一个视图对象 -
dict.keys():返回一个视图对象 -
dict.setdefault(key, default=None):和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default -
dict.update(dict2):把字典dict2的键/值对更新到dict里 -
dict.values():返回一个视图对象 -
pop(key[,default]):删除字典key(键)所对应的值,返回被删除的值。 -
popitem():返回并删除字典中的最后一对键和值。
十二. 集合 Set
12.1 什么是集合
集合(set)是一个无序的不重复元素序列。集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。创建一个空集合必须用 set() ,因为 { } 是用来创建一个空字典。
1 | parame1 = {value01,value02,...} |
12.2 集合基本操作
12.2.1 添加元素
s.add(x) ,将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
s.update(x) 也可以添加元素,且参数可以是列表,元组,字典等。
1 | s = {1, 3} |
12.2.2 移除元素
s.remove(x) ,将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
s.discard(x) ,将元素 x 从集合 s 中移除,如果元素不存在,不会发生错误。
s.pop() ,随机删除集合中的一个元素。
12.2.3 计算集合元素个数
len(s) ,计算集合 s 元素的个数。
12.2.4 清空集合
s.clear() ,清空集合 s 。
12.2.5 判断元素是否在集合中
x in s ,存在返回True,不存在返回False。
12.3 集合的方法
-
add():为集合添加元素 -
clear():移除集合中的所有元素 -
copy():拷贝一个集合 -
difference():返回多个集合的差集 -
difference_update(),移除集合中的元素,该元素在指定的集合也存在。 -
discard(),删除集合中指定的元素 -
intersection(),返回集合的交集 -
intersection_update(),返回集合的交集。 -
isdisjoint(),判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 -
issubset(),判断指定集合是否为该方法参数集合的子集。 -
issuperset(),判断该方法的参数集合是否为指定集合的子集 -
pop(),随机移除元素 -
remove(),移除指定元素 -
symmetric_difference(),返回两个集合中不重复的元素集合。 -
symmetric_difference_update(),移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 -
union(),返回两个集合的并集 -
update(),给集合添加元素
具体使用解释可自行搜索。
十三. 迭代器和生成器
13.1 迭代器
迭代器是一个可以 记住遍历的位置 的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:
-
iter():创建一个迭代器对象。 -
next():返回下一个迭代器对象。
字符串,列表或元组对象都可用于创建迭代器。
举个例子:
1 | list = [1, 2, 3, 4] |
还可以把一个类作为一个迭代器使用,需要实现 __iter__() 和 __next__() 方法。此处举例:创建一个返回数字的迭代器,初始值为 1,逐步递增 1。
1 | class MyNumbers: |
当迭代完成时,会触发 StopIteration ,可以在 __next__() 中设置。
1 | class MyNumbers: |
13.2 生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回。
然后,每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
调用一个生成器函数,返回的是一个迭代器对象。
下面是一个简单的示例,展示了生成器函数的使用:
1 | def countdown(n): |
再举一个例子,计算斐波那契数列:
1 | import sys |
十四. 推导式
14.1 列表推导式
格式为:
1 | # [表达式 for 变量 in 列表] |
-
out_exp_res:列表生成元素表达式,可以是有返回值的函数。
-
for out_exp in input_list:迭代input_list将out_exp传入到out_exp_res表达式中。
-
if condition: 条件语句,可以过滤列表中不符合条件的值。
推导出来是一个列表。
举个例子,求30以内能被4整除的整数:
1 | ans = [i for i in range(30) if i % 4 == 0] |
再举个例子,求列表中长度大于3的字符串并大写:
1 | list = ["aaa", "aasdad", "asdw", "wadhjuio"] |
14.2 字典推导式
格式为:
1 | { key_expr: value_expr for value in collection } |
原理与列表推导式类似,推导出来的是一个字典。看一个例子,给出三个数字作为键,以对应的平方作为值,创建字典:
1 | list = [4, 2, 8] |
再来一个例子,以列表中偶数索引为键,奇数索引为值创建字典:
1 | list = ['apple', '苹果', 'banana', '香蕉'] |
14.3 集合推导式
格式为:
1 | { expression for item in Sequence } |
原理类似,推导出来的是一个集合。
14.4 元组推导式(生成器表达式)
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
格式为:
1 | (expression for item in Sequence ) |
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [] ,另外元组推导式返回的结果是一个生成器对象。需要使用 tuple() 函数,可以直接将生成器对象转换成元组。
1 | a = (x for x in range(1,10)) |
十五. 文件的读写
15.1 打开文件
Python的 open() 方法用于打开一个文件,并返回文件对象。注意打开文件使用完后记得关闭文件 close()
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError 异常。
该函数的完整格式为:
1 | open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) |
-
file: 必需,文件路径(相对或者绝对路径)。
-
mode: 可选,文件打开模式
-
buffering: 设置缓冲
-
encoding: 一般使用utf8
-
errors: 报错级别
-
newline: 区分换行符
-
closefd: 传入的file参数类型
-
opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
一般情况下,只需传入file参数和mode参数即可。
mode参数有:
-
t:文本模式 (默认)。 -
x:写模式,新建一个文件,如果该文件已存在则会报错。 -
b:二进制模式。 -
+:打开一个文件进行更新(可读可写)。 -
r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 -
rb:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 -
r+:打开一个文件用于读写。文件指针将会放在文件的开头。 -
rb+:以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 -
w:打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 -
wb:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 -
w+:打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 -
wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 -
a:打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 -
ab:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 -
a+:打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 -
ab+:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
15.2 文件对象的方法
使用 open() 函数会创建一个file对象,file对象有以下常用函数:
-
file.close():关闭文件。关闭后文件不能再进行读写操作。 -
file.flush():刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 -
file.fileno():返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 -
file.isatty():如果文件连接到一个终端设备返回 True,否则返回 False。 -
file.read([size]):从文件读取指定的字节数,如果未给定或为负则读取所有。 -
file.readline([size]):读取整行,包括 “\n” 字符。 -
file.readlines([sizeint]):读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 -
file.seek(offset[, whence]):移动文件读取指针到指定位置 -
file.tell():返回文件当前位置,是从文件开头开始算起的字节数。 -
file.truncate([size]):从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 windows 系统下的换行代表2个字符大小。 -
file.write(str):将字符串写入文件,返回的是写入的字符长度。 -
file.writelines(sequence):向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
方法众多,需要时再查阅资料再学习。
15.3 读取文件
file.read() 方法:
-
为了读取一个文件的内容,调用
file.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。 -
size是一个可选的数字类型的参数。 当size被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
1 | # test.txt中内容: |
file.readline() 方法:
file.readline()会从文件中读取单独的一行。换行符为 ‘\n’。file.readline()如果返回一个空字符串, 说明已经已经读取到最后一行。
1 | # test.txt中内容: |
file.readlines() 方法:
f.readlines()将返回该文件中包含的所有行。如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
1 | # test.txt中内容: |
15.4 文件写入
file.write() 方法:
f.write(string)将 string 写入到文件中, 然后返回写入的字符数。
1 | # test.txt中为空 |