记录一次环境配置
OpenCV的环境配置
OpenCV下载安装
前往官网选择适合的OpenCV版本下载,并安装到合适的位置。
我的OpenCV安装在:D:\opencv4.5.2
添加OpenCV到系统Path变量
打开编辑系统环境变量,点击右下方的环境变量,在系统变量中找到PATH项,点击编辑添加OpenCV目录下的bin文件夹。
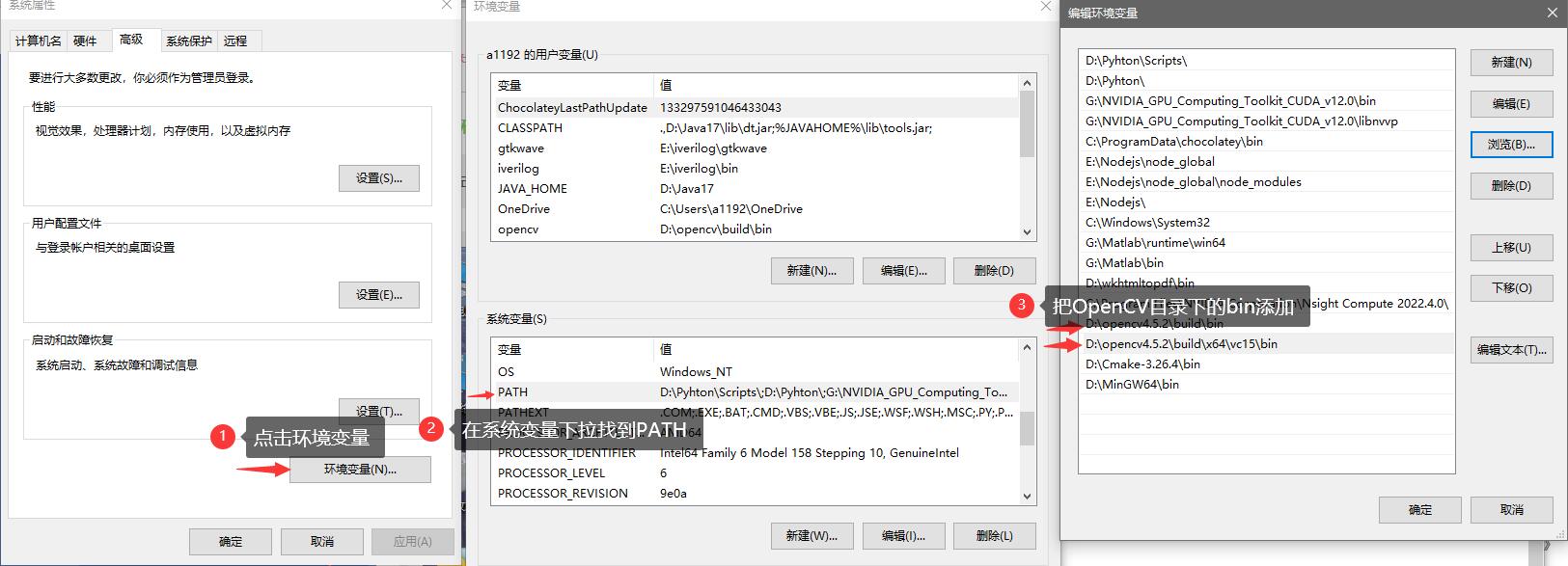
至于添加的是vc14还是vc15,参照下表
| VS版本 | VC |
|---|---|
| VS2015 | VC14 |
| VS2017及以上 | VC15 |
添加OpenCV环境到VS项目
右键项目,选择最下方属性,打开属性配置窗口,选择是Debug模式或Release模式配置。

VC++目录配置OpenCV
- 点击包含目录,在包含目录中把OpenCV目录下的include文件夹添加。
此处我的添加是:
1 | D:\opencv4.5.2\build\include\opencv2 |
- 点击库目录,在库目录中把OpenCV的lib文件添加,此处路径藏得比较深,参考我的添加。
此处我的添加是:
1 | D:\opencv4.5.2\build\x64\vc15\lib |
链接器配置OpenCV
- 点击输入,再点击附加依赖项,将OpenCV的lib文件添加,lib文件存放在上面库目录的文件夹中。
1 | opencv_world452.lib |
注意,此处文件名带d的为Debug版本的依赖项,不带d的为Release版本的依赖项。
在配置Debug版本时把带d的文件放在不带d的文件之上,
在配置Release版本时把不带d的文件放在带d的文件之上。
如果显示找不到opencv_worldxxx.dll ,请把opencv_worldxxx.dll的路径添加到系统环境变量。
CUDA环境配置
CUDA下载安装
我的CUDA目录在:G:\NVIDIA_GPU_Computing_Toolkit_CUDA_v12.0
添加CUDA环境到VS项目
配置为x64平台。
右键项目→生成依赖项→生成自定义→勾选“CUDA xxx”。

VC++目录配置CUDA
- 点击包含目录,在包含目录中把OpenCV目录下的include文件夹添加。
此处我的添加是:
1 | G:\NVIDIA_GPU_Computing_Toolkit_CUDA_v12.0\include |
- 点击库目录,在库目录中把OpenCV的lib文件夹添加。
此处我的添加是:
1 | G:\NVIDIA_GPU_Computing_Toolkit_CUDA_v12.0\lib\x64 |
链接器配置CUDA
- 点击常规,再点击附加库目录,添加下面的目录。似乎不配置这一条也可以
1 | $(CUDA_PATH_V12_0)\lib\$(Platform) |
或
1 | G:\NVIDIA_GPU_Computing_Toolkit_CUDA_v12.0\lib\x64 |
- 点击输入,再点击附加依赖项,将CUDA的lib文件添加,输入下面的内容。
1 | G:\NVIDIA_GPU_Computing_Toolkit_CUDA_v12.0\lib\x64\*.lib |
配置源码文件风格
右键源文件,可以添加新建项中选择“CUDA C/C++ File”。
右键“xxx.cu”源文件,点击属性,选择配置属性中的常规,从项类型中找到“CUDA C/C++”。
测试CUDA代码
1 |
|
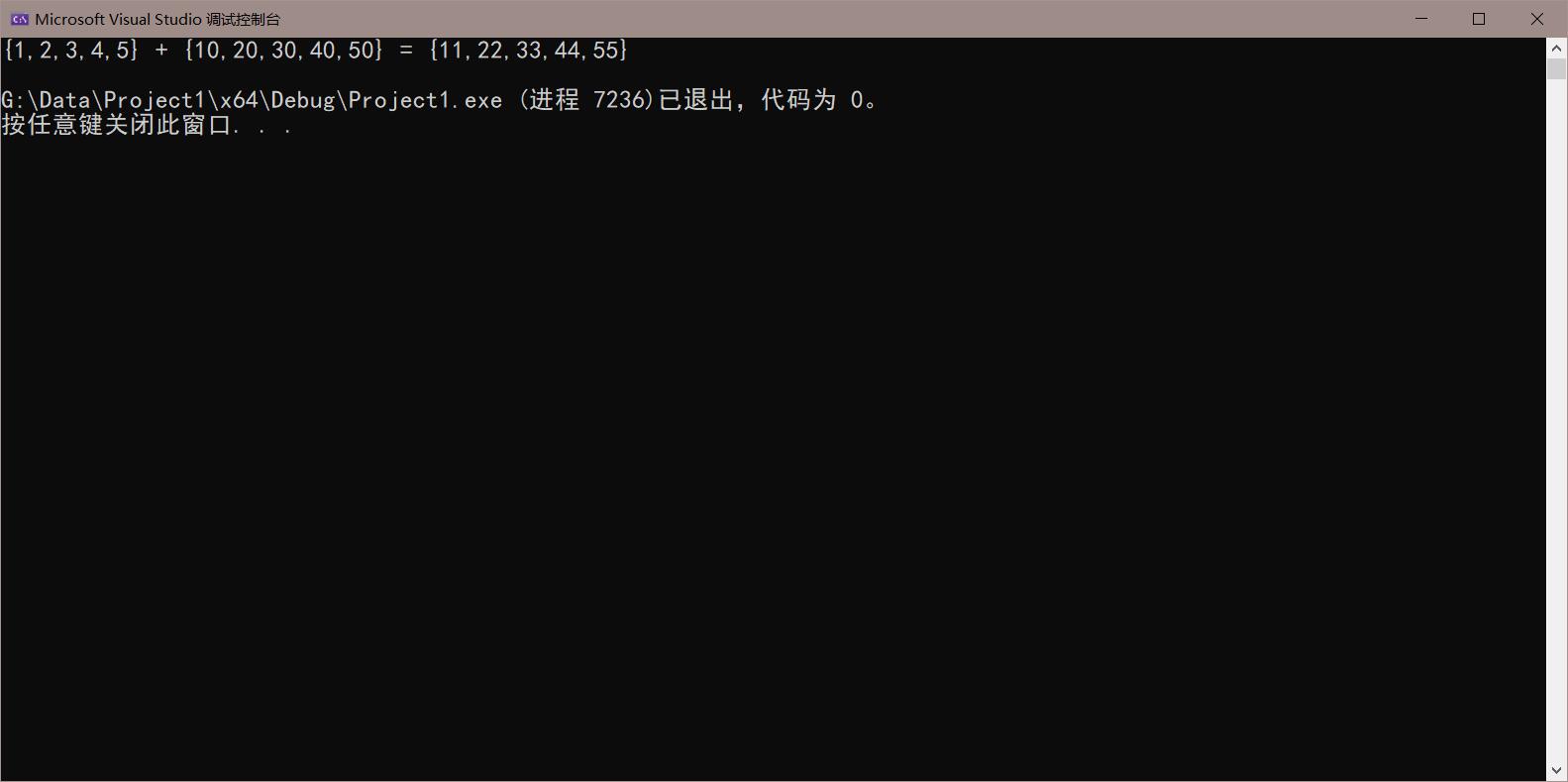
运行结果如下图:
CUDA环境的一些碰壁
-
我的CUDA安装在一个可移动固态硬盘(G盘)中,可能导致了我的CUDA项目只能位于G盘使用,复制粘贴到电脑的盘会出现问题。
-
如果出现了大段指令无法运行,像下面的错误显示,可以复制命令(引号部分)到cmd运行,查看更详细的报错原因。
1 | // VS报错如下 |
- 还遇到一些其他的坑可以自行必应。